SJVIK LABS · SJVIKLABS.COM
Practitioner-built tools for cybersecurity and DevOps work.
Books, templates, and configurations from a 3-node production cluster I run in my condo. Built because I needed them. Sold because other practitioners asked. Not a consultancy. Not a SaaS pitch. Just things that work.
15 guides, kits, and bundles
Build the cluster, then everything on it
One production homelab, documented guide by guide. Start with the base build, add the pieces you need.


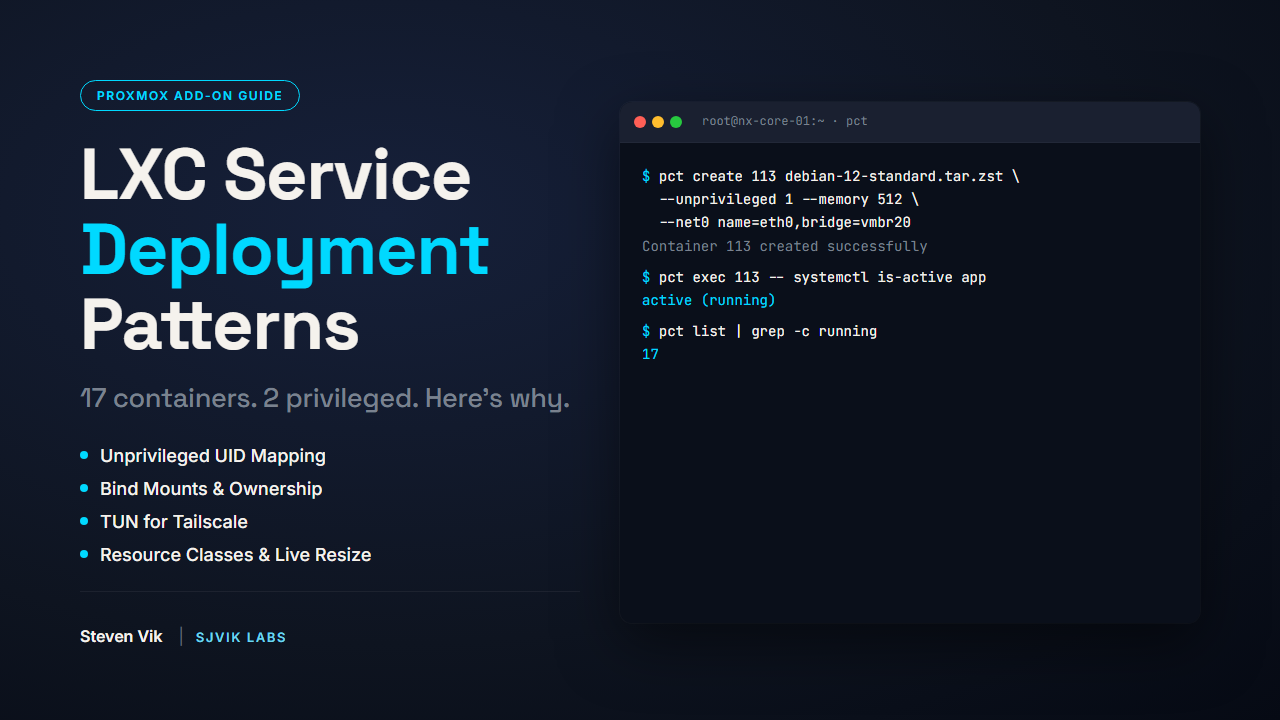

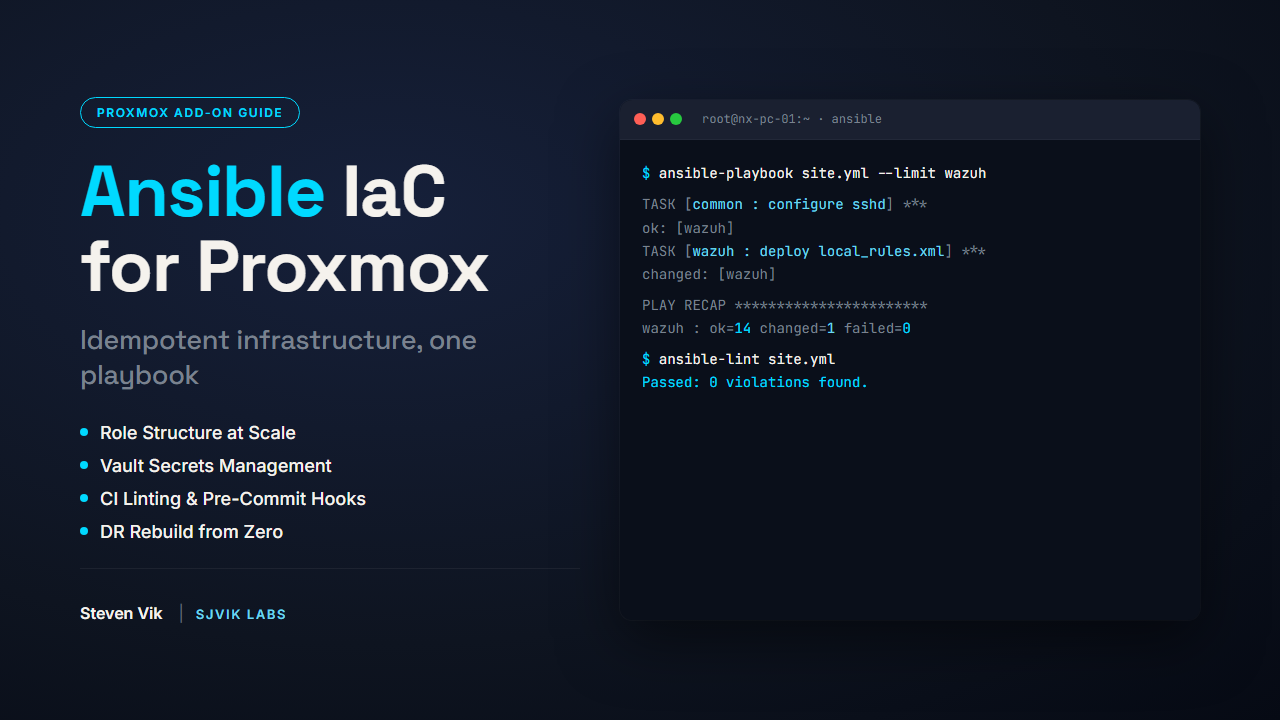
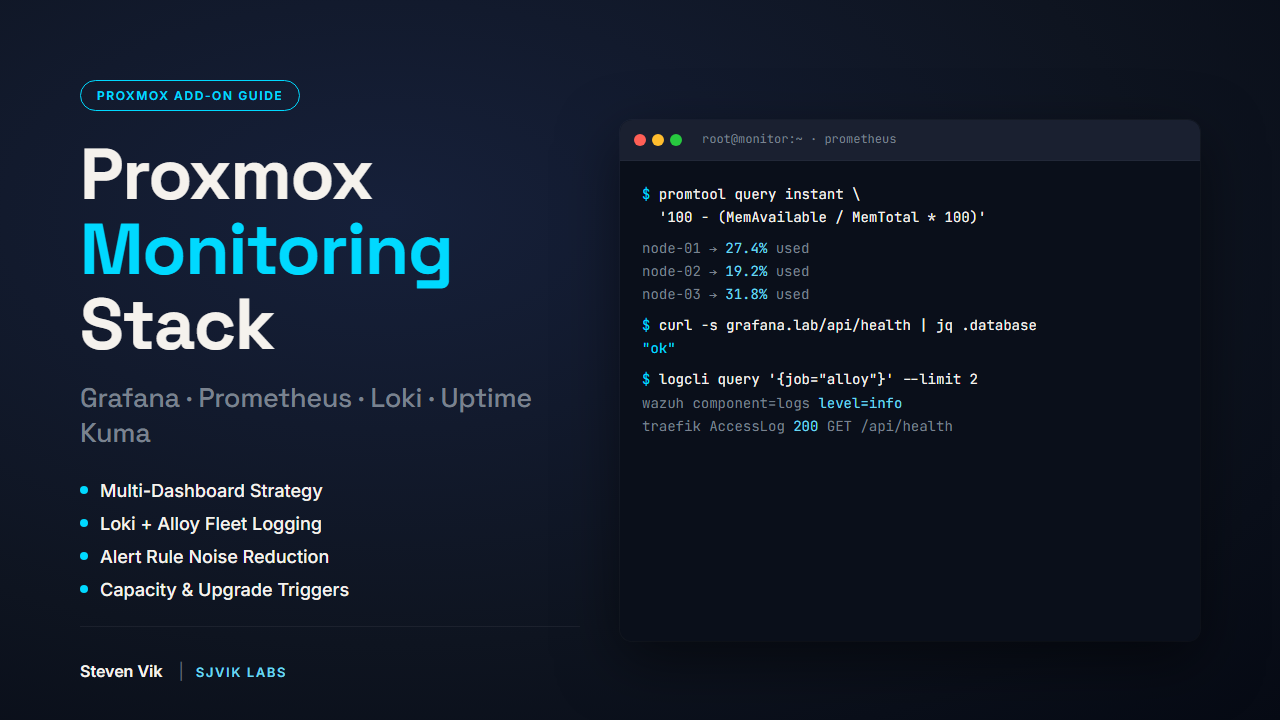
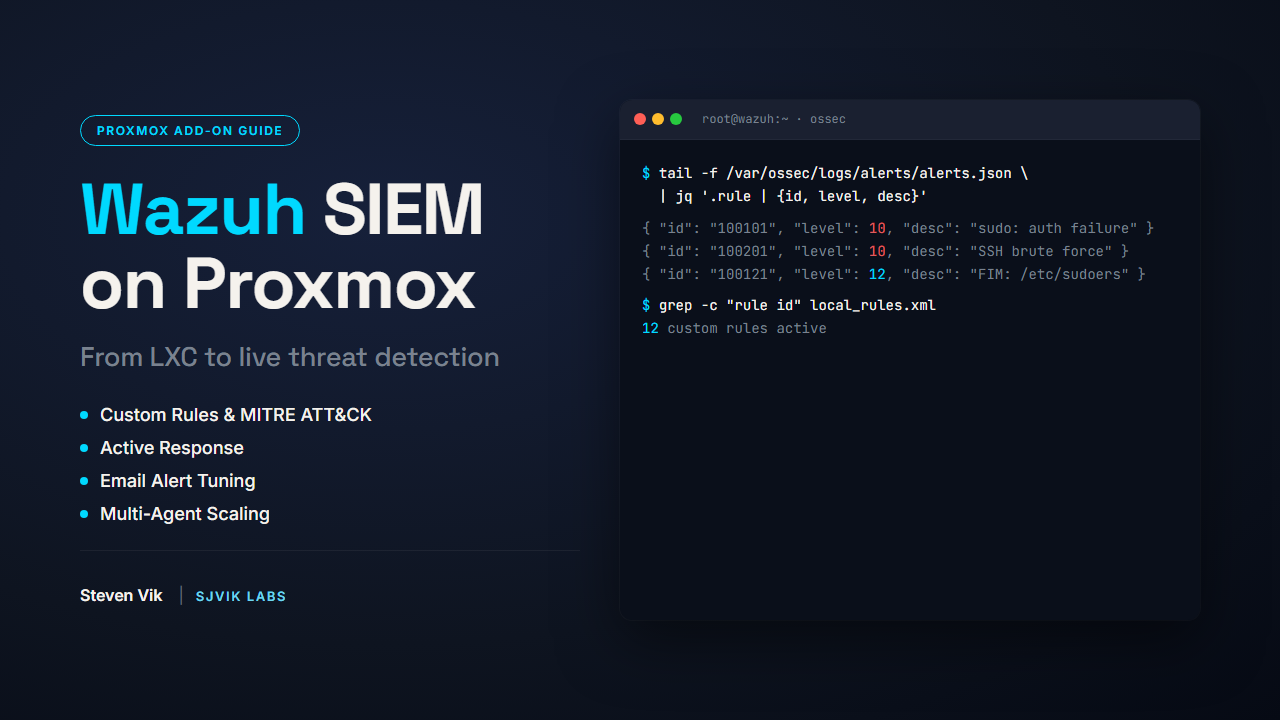
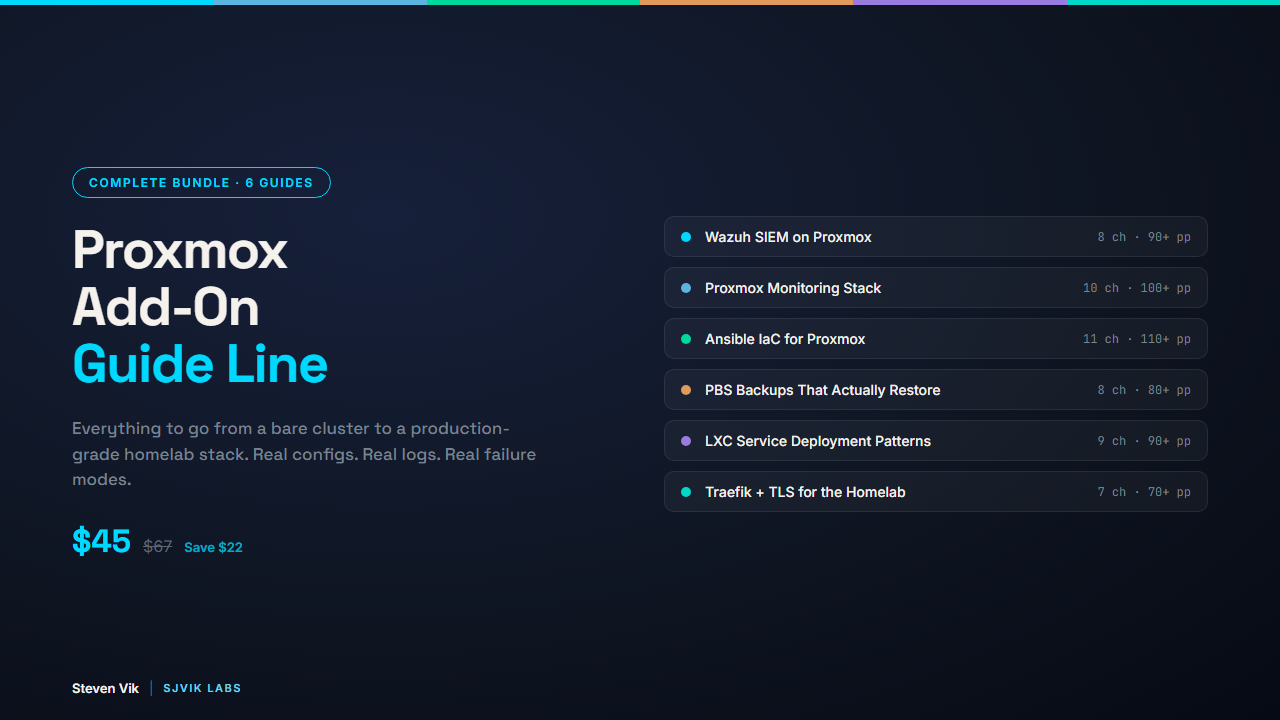 BUNDLE
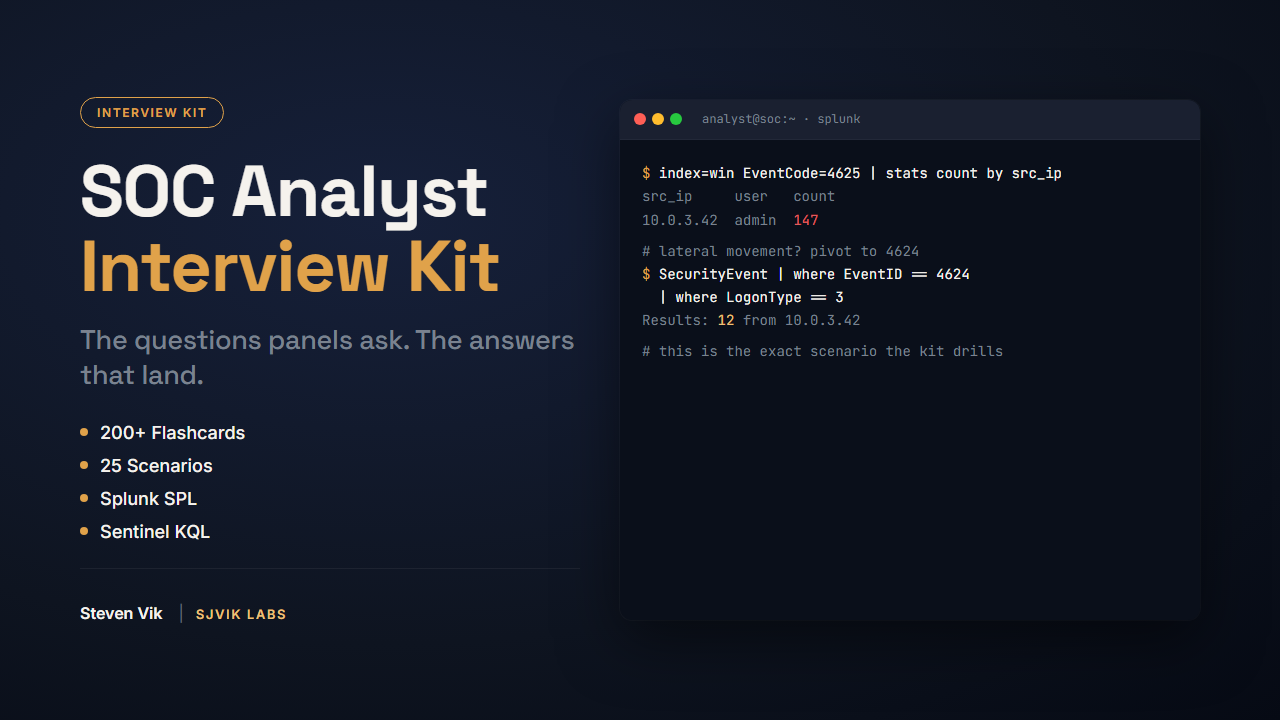
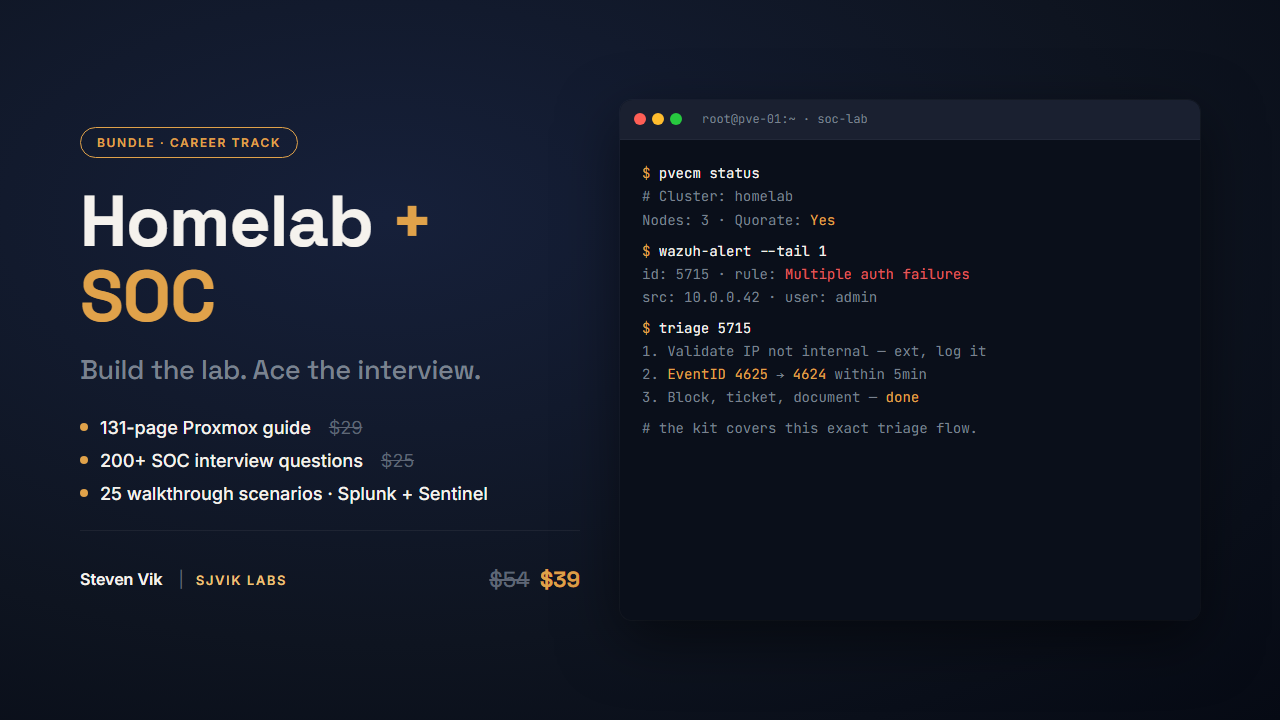
BUNDLE Break into the SOC
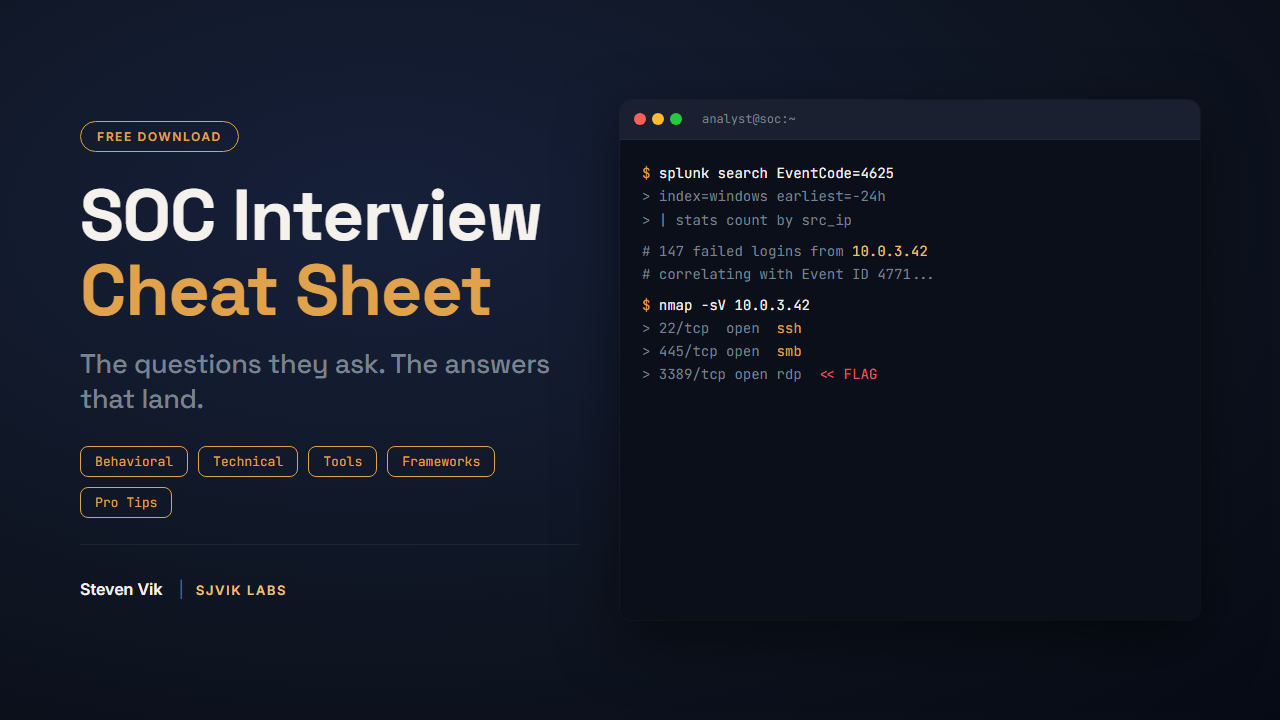
The interview prep that got me through the door, plus a free reference to start with.
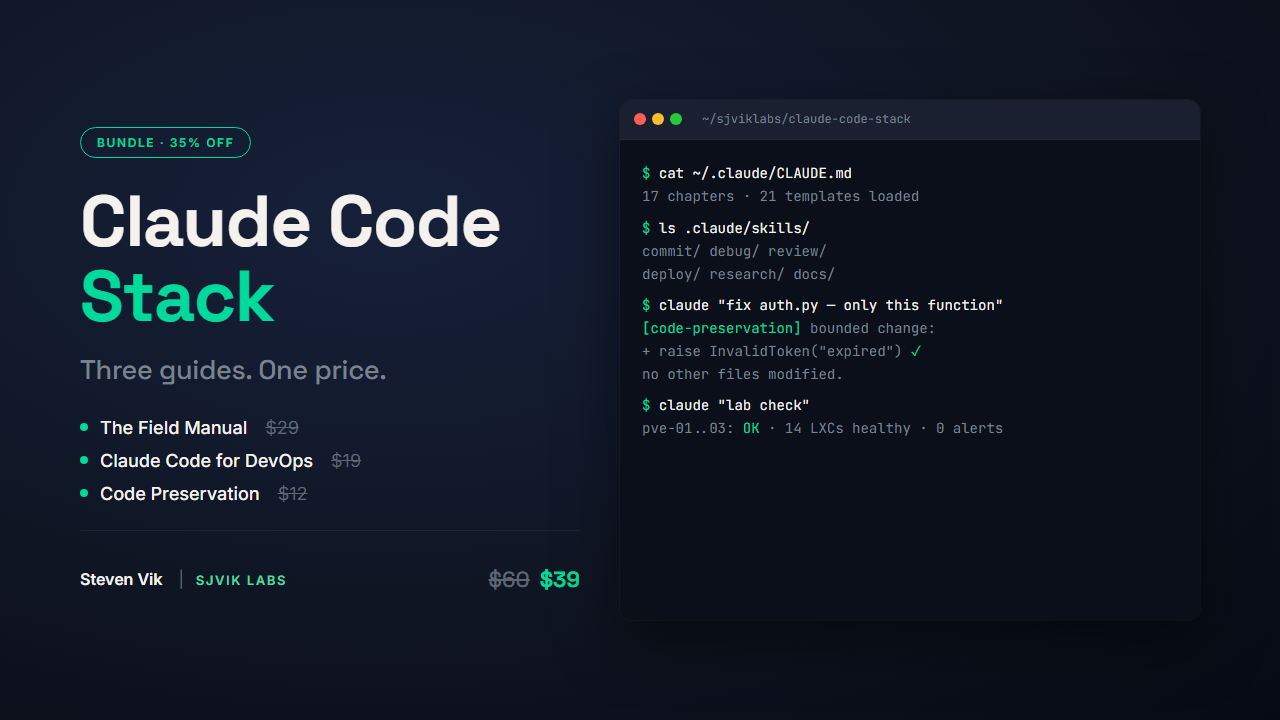
Work the way I work with Claude Code
Patterns, templates, and prompts from living in Claude Code every day.



Security & infra tooling
Wazuh detections, Sigma rules, and IR playbooks. Battle-tested in a live SOC workflow — the same detections I run in production.
Ansible roles for Traefik, AdGuard, node_exporter, and Tailscale. The backbone of my 3-node cluster, packaged for reuse.
Engineering journal — operational failures, design decisions, and the things I got wrong. Posted on the personal site, mirrored back here.